Architecture
The key data type of Chronix is called a record. It stores a chunk of time series data in a compressed binary large object. The record also stores technical fields, time stamps for start and end, that describe the time range of the chunk of data, and a set of arbitrary user-defined attributes. Storing records instead of individual pairs of time stamp and value has two major advantages:
- A reduced storage demand due to compression
- Almost constant query times for accessing a chunk due to indexable attributes and a constant overhead for decompression.
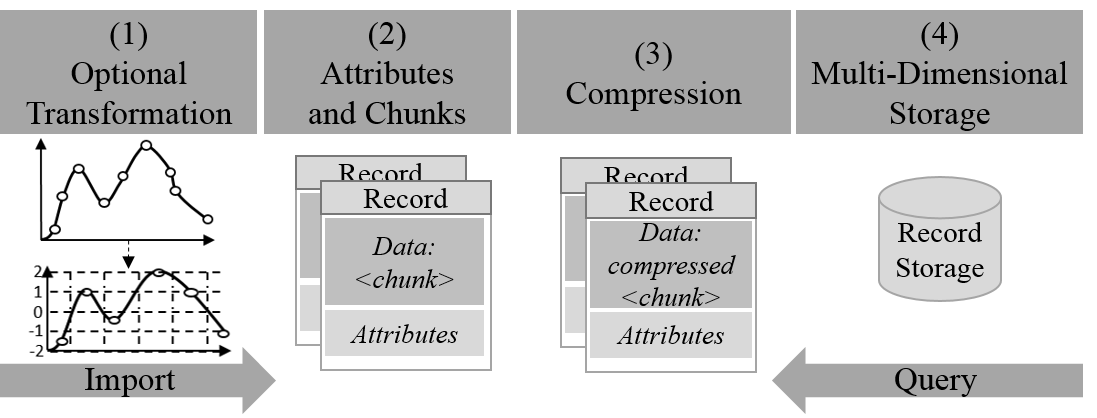
The architecture of Chronix has the four building blocks shown in Figure. It is well-suited to the parallelism of multi-core systems. All blocks can work in parallel to each other to increase the throughput.
Optional Transformation
Optional Transformation is optional (as the name implies) and reduces the amount of time series with the goal of storing fewer records. It uses techniques that exploit knowledge on the shape and the significance of a time series to remove irrelevant details even if some accuracy is lost, e.g. dimensionality reduction through aggregation.
Attributes and Chunks
Attributes and Chunks breaks down time series into chunks of n data points that are serialized into c Bytes. It also calculates the attributes and the pre-calculated values of the records. Part of this serialization is a Date-Delta Compaction that compares the deltas between time stamps. It serializes only the value if the aberration of two deltas is within a defined range, otherwise it writes both the time stamp and the value to the record's data field.
Basic Compression
Then Basic Compression uses gzip, a lossless compression technique that operates on c consecutive bytes. Only the record's data field is compressed to reduce the storage demand while the attributes remain uncompressed for access. Compression of operational time series data yields a high compression rate due its value characteristics. In spite of the decompression costs when accessing data, compression actually improves query times as data is processed faster.
Multi-Dimensional Storage
The Multi-Dimensional Storage holds the records in a compressed binary format. Only the fields that are necessary to locate the records are visible as so-called dimensions to the data storage system. Queries can then use any combination of those dimensions to locate records. Chronix uses Apache Solr as it ideally matches the requirements. Furthermore Chronix has built-in analysis functions, e.g, a trend and outlier detector, to optimize operational time series analyses.