Chronix Ingester
To efficiently store time series in Chronix, a metrics source needs to send time series data in a chunked format, with a chunk containing multiple samples. However, external metrics sources don't necessarily support sending chunked data. For example, Prometheus can only send a stream of individual samples via its remote write interface.
The Chronix Ingester solves this problem. It is a process that sits between a metrics source and Chronix. For each incoming series, it batches up samples before sending them as chunks to Chronix. Currently, only Prometheus is supported as a metrics source:

Chunking
The ingester needs to batch up incoming samples for each series before writing out an entire chunk. To achieve this, the ingester maintains an in-memory hash table of series and their unwritten sample chunks. The key into this hash table is a series identifier (a hash over the metric name and all of its attributes). The associated hash value is a list of unpersisted chunks belonging to that series:
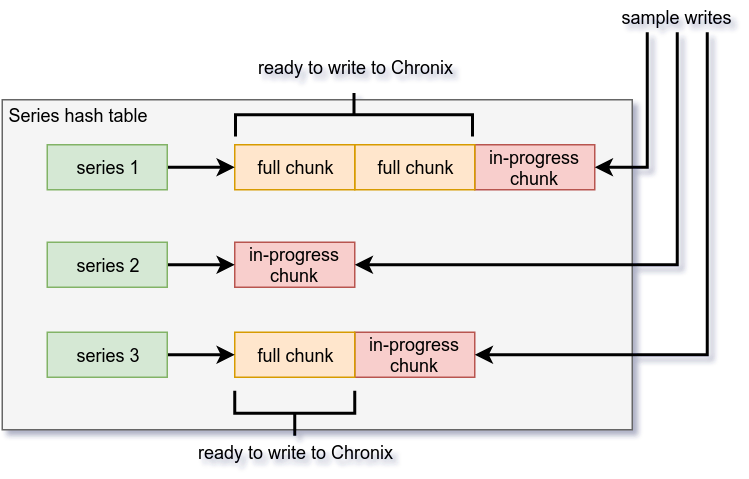
For each active series, the ingester may keep several chunks in memory: at least one in-progress chunk to which incoming samples are appended, and possibly one or more full chunks which have not been written out to Chronix yet. As a chunk has a fixed size in memory (currently 1kB), it will eventually become full. The ingester routinely persists any full chunks to Chronix. Once a chunk has been successfully written to Chronix, it is removed from the ingester's memory. Since it may take hours or even days for a chunk to become full, chunks with available space are also persisted to Chronix when the first sample in the chunk is older than a configurable maximum age.
Crash and Restart Resilience
Since the ingester batches up samples for each series in memory before persisting them to Chronix as chunks, it holds some amount of transient state (up to the configurable maximum chunk age). This in-progress memory chunk state should not be lost when the process restarts or crashes.
To guard against this, the ingester writes checkpoints of its entire in-memory state to a single file on disk. Checkpoints are written both periodically and upon orderly shutdown. When the ingester restarts, it loads the saved checkpoint into memory and then resumes normal operation. This design allows for recovery from crashes or restarts, but does not protect against failures of the entire machine or its disk. The maximum time window that can be lost with this approach in case of a crash is the configurable period between checkpoints. During orderly shutdown, an ingester may alternatively be configured to flush its pending in-memory state to Chronix instead of writing it to a local checkpoint.
An alternative log-based recovery approach would not have worked well here: since chunks for different series may fill up at very different rates and will then be persisted to Chronix, a single log file would quickly grow "holes" and would need to be continuously compacted. Compaction and recovery from the log would further require knowing which samples in the log have already been persisted as part of a full chunk. Essentially, to handle a time-series scenario with a log-based approach, we would need a log per series. This is infeasible for millions of series given usual disk IO characteristics. Thus, we only batch up samples per series in memory and periodically write out simple linear checkpoints of that in-memory state.
Implementation
The Chronix Ingester is written in Go and is available on GitHub. See there for exact usage and build instructions.
To receive samples, it supports Prometheus's remote write protocol.
To serialize and send time series chunks to Chronix, it uses the Chronix client library for Go.
For a space-efficient batching of samples into chunks in memory, the ingester reuses Prometheus's chunk encoding implementation.